开云(中国)2026世界杯版IOS|Android手机app下载 牛津、英伟达等提议记忆压缩新范式: 西宾时让模子学会断舍离
发布日期:2026-06-15 05:40 点击次数:201


剪辑|Panda
2026 年头,各大 AI 厂商在高下文窗口长度上张开热烈角逐。Google 的 Gemini 3 Pro 已援救 100 万级 token 高下文,Meta 的 Llama 4 Scout 更宣称可责罚 1000 万 token。GPT-5 系列也在快速鼓励长高下文智商。
按这个趋势,今天的大模子依然约略邻接读竣工套《哈利・波特》,未来致使可能凯旋分析悉数大型代码仓库。
但数字背后也荫藏着一个环节问题:高下文越长,模子就越「记不住」。
这并非模子不够贤达,而是 Transformer 架构自己的工程不休。当模子责罚长文本时,需要为每个 token 保存 Key-Value(KV)景象,用于后续生成时的郑重力诡计。这个缓存区域被称为 KV Cache。
KV Cache 的大小会随高下文长度线性增长:输入越长,占用的 GPU 显存越多,推理速率也越慢。关于百万 token 级别的输入,在大型模子和高精度推理场景下,KV Cache 的内存支拨可达到数十到数百 GB,远超单张顶级 GPU 的显存容量。
高下文窗口的竞赛,实质上是一场显存的干戈。
面临这一逆境,究诘者们依然斥地出多种「过后压缩」决策,也即是在模子西宾完成之后,用多样算法对 KV 缓存进行精简。这些环节确乎有用,但它们齐遗漏了一个更根蒂的问题:要是模子在来源学习的时辰,就莫得被调换去生成「容易被压缩」的里面暗示,那么后期不管如何压缩,后果齐将受到天花板死心。
就在这一配景下,来自牛津大学、以色列理工学院、AITHYRA 和英伟达的纠合究诘团队提议了一个新的想路:与其过后弥补,不如西宾时就让模子主动学会「压缩友好」的记忆步地。

他们将这套环节定名为 KV-CAT(KV 压缩感知型西宾,KV-Compression Aware Training)。

论文标题:Training Transformers for KV Cache Compressibility
论文地址:https://arxiv.org/abs/2605.05971
KV 缓存为如何此难压缩?
要意会这项究诘的价值,先得弄明晰一个直观上看似奇怪的事实:两个输出统统通常的模子,其 KV 缓存可能一个极易压缩,另一个根蒂无法压缩。
这听起来很反直观。咱们常常合计,要是两个系统的「终结」通常,它们的里面过程应该莫得实质区别。但在神经采集寰球里并非如斯。
究诘团队用一个简便的例子来诠释这少量:「词频统计」。给模子输入一段笔墨,让它统计每个字母出现了几许次。这是一个只依赖「汇总信息」的任务,与每个字母出现的王法无关。
同样完成这个任务,不错有两种判然不同的里面终结步地。
第一种是「自关系词然」的终结:模子对每个 token 进行孤苦编码,临了通过郑重力机制对悉数 token 作念平均,得出统计终结。这种环节简便凯旋,AG百家乐APP中国官方下载但存在一个致命残障:任何对 KV 缓存的压缩齐会冲破平均诡计,导致最终终结出错。究诘团队从数学上解释了:这种终结步地,在表面上对任何进程的压缩齐不具备容错智商。
第二种是「结构化」的终结:模子在责罚每个 token 时,绝顶记载序列的位置信息(即这段前缀有多长),当 KV 缓存被压缩成一个单一的向量时,模子不错驾御位置信息对压缩后的汇总值进行再行校准,从而收复正确的统计终结。这种终结步地,表面上不错将恣意长度的前缀压缩到仅剩一双 KV 向量,同期保抓零迂回。
两种终结,通常的输出,判然不同的压缩性。
环节在于:步伐的模子西宾过程,统统莫得引发让模子去选拔第二种更结构化的终结。因为在莫得压缩的场景下,两种步地后果统斡旋样,西宾信号无从分辩。
中枢环节
让模子在「戴着镣铐」的情况放学习
意识到这少量后,究诘团队联想了 KV-CAT 西宾决策。中枢想路极为凯旋:要是你想让模子学会在 KV 缓存被压缩的情况下闲居责任,就在西宾时模拟这种压缩压力。
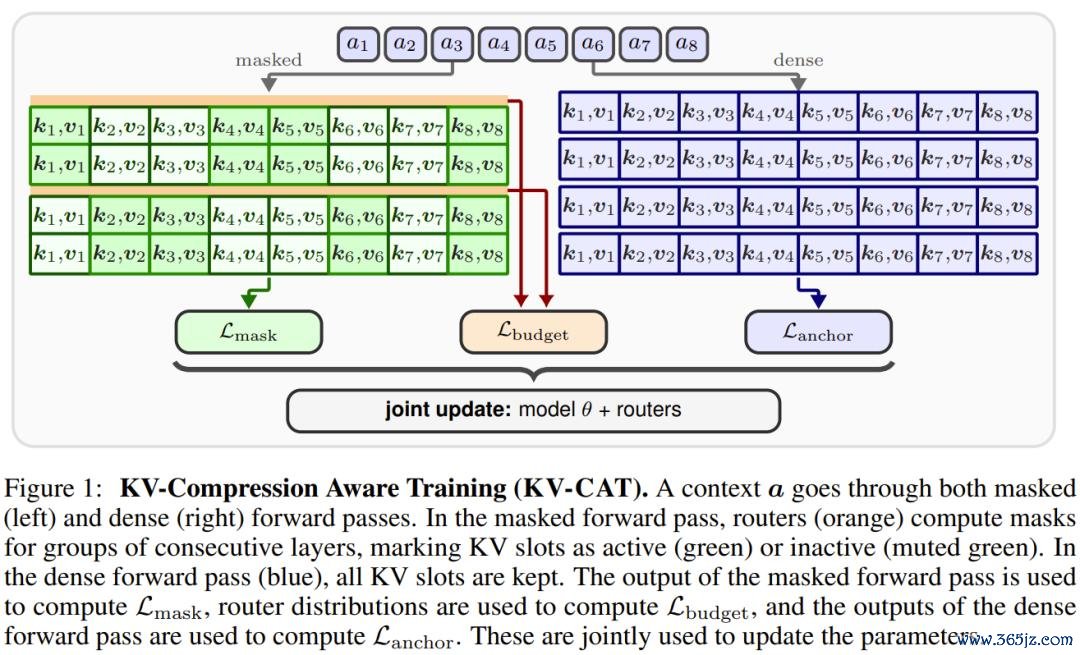
这雷同于一种「记忆装潢西宾」。世俗的模子西宾就像让学生在查考时不错带着竣工的札记本作答 —— 诚然发扬优异。而 KV-CAT 则是在西宾时就充公大部分札记,开云(中国)2026世界杯版IOS|Android手机app下载逼着学生将最迫切的信息内化成果真的「意会」,而非对札记的依赖。
具体来说,KV-CAT 在原有的预西宾模子基础上,引入了一组轻量级的「路由器」模块。这些路由器在西宾的每一步会动态判断哪些 KV 槽位是必要的、哪些不错被屏蔽,贪图是保留约 50% 的 KV 缓存。每次前向传播,模子需要同期进行两次诡计:一次是闲居的「全量」诡计(通盘 KV 槽位齐可见),一次是「压缩」诡计(仅保留路由器选中的 KV 槽位)。
西宾贪图由三部分构成:
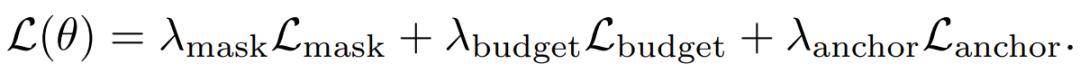
自蒸馏吃亏,让压缩模式下的输出尽量靠拢全量模式下的输出;
锚定吃亏,凯旋对全量模式施加步伐的下一个词瞻望贪图,确保模子的基础智商不退化;
预算吃亏,不休路由器施行保留的 KV 比例不偏离 50% 的贪图太多。
悉数过程完成后,路由器模块在推理时会被关闭。输出的是一个步伐的 Transformer 模子,它的参数与原模子通常,但其里面依然被西宾成一种「自然压缩友好」的暗示样式。后续不错搭配恣意现成的 KV 压缩环节使用。
详备的数学态状请探望原论文。
实验终结
全面向上,且不以基础智商为代价
究诘团队将 KV-CAT 应用于 Qwen2.5 的两个边界版块(0.5B 和 1.5B 参数),并在多个维度上对其进行评估。
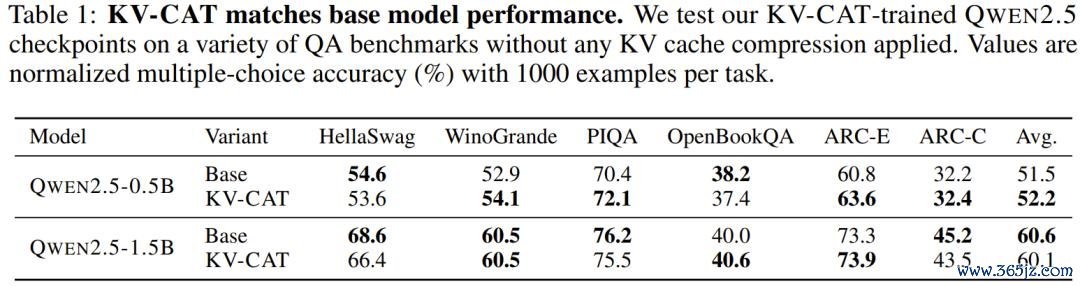
来源,基础智商莫得吃亏。 这是最环节的考证。在六个步伐多选题基准测试上(包括 HellaSwag、WinoGrande、ARC 等),KV-CAT 西宾后的模子与原始模子险些抓平:0.5B 版块平均耕种了 0.7 个百分点,1.5B 版块平均着落了 0.5 个百分点,均属于闲居的西宾波动范围。这诠释 KV-CAT 莫得以点火通用智商为代价换取压缩性能。
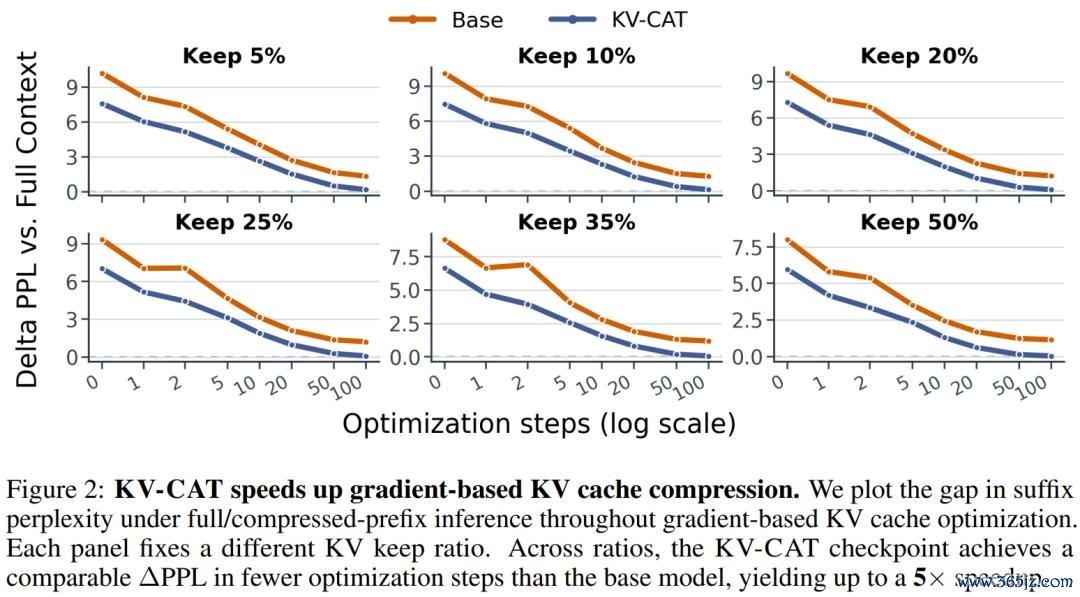
其次,后期 KV 压缩的后果大幅改善。 在同等压缩预算下,与原始基础模子比较:
使用郑重力匹配(Attention Matching)环节对前缀进行压缩后,续写文本的困惑度(perplexity)差距最多松开了 3.21 倍 —— 也即是说,压缩后模子的发扬与压缩前更为接近。
使用梯度优化法进行压缩时,KV-CAT 模子达到通常压缩质地所需的优化步数减少了最多 5 倍。这对施行部署至关迫切:压缩自己也需要诡计资源,要是压缩速率更快,就意味着不错责罚更多恳求。
第三,「大海捞针」检索准确率权臣耕种。 究诘团队联想了一个经典的长文检索测试:在一段充满滋扰项的长文本(约 1024 个 token)中藏入一个六位数的「密码」,然后将文本的 KV 缓存压缩后,测试模子能否正确回忆出这个密码。
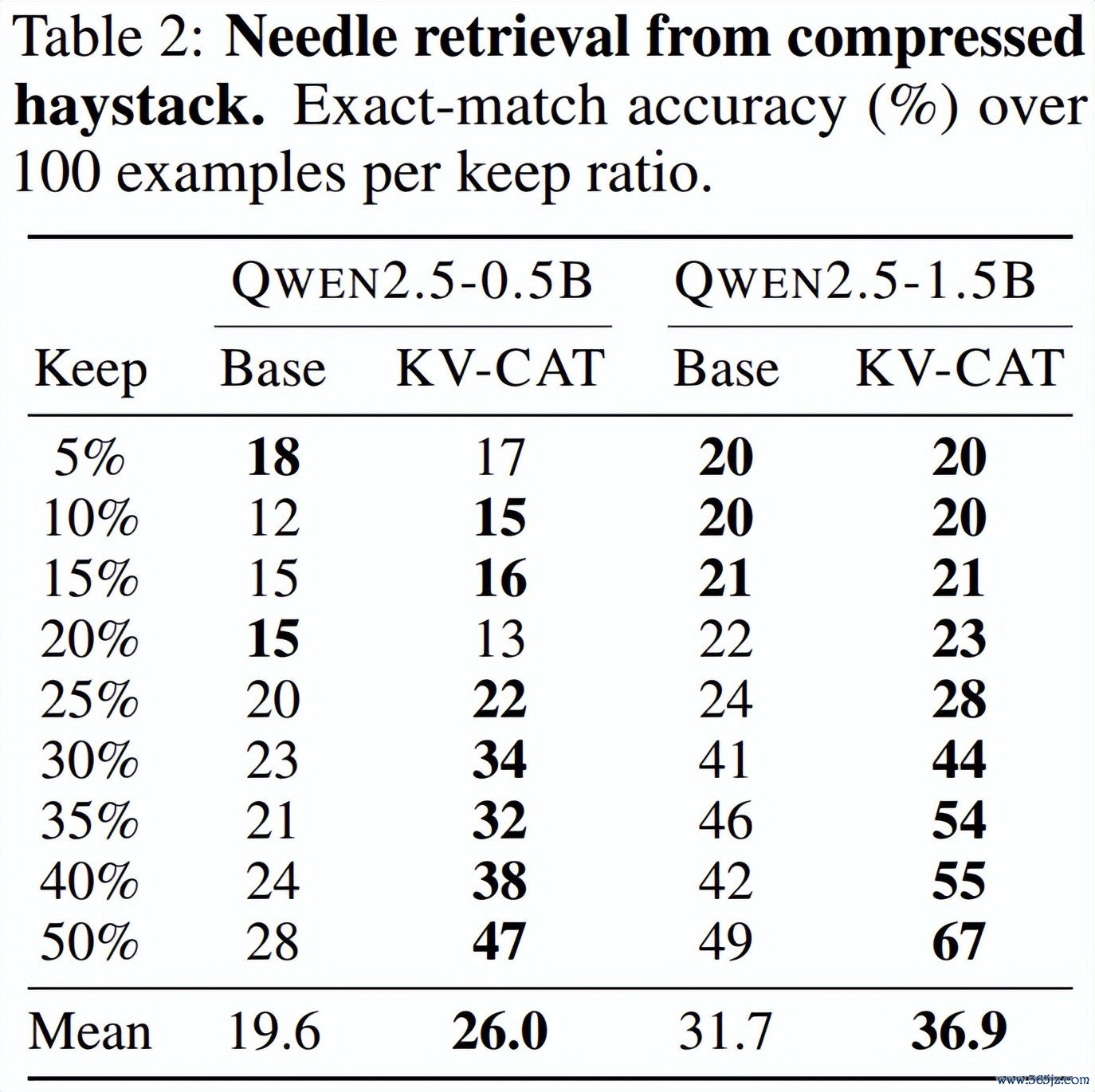
在保留 50% 的 KV 槽位的情况下,KV-CAT 版块的 Qwen2.5-0.5B 检索准确率从 28% 跃升至 47%,Qwen2.5-1.5B 则从 49% 耕种至 67%,耕种幅度接近 68%。即使在极点压缩(仅保留 10% 的 KV)的情况下,KV-CAT 版块的性能也与基础模子在轻度压缩时十分。
第四,长文问答任务也有昭彰改善。 在 LongBench v2 的七项长文本问答任务上,KV-CAT 模子在各压缩比例下的平均准确率均高于基础模子,最大耕种幅度达到 39%。
开云体育app2026世界杯中国官网下载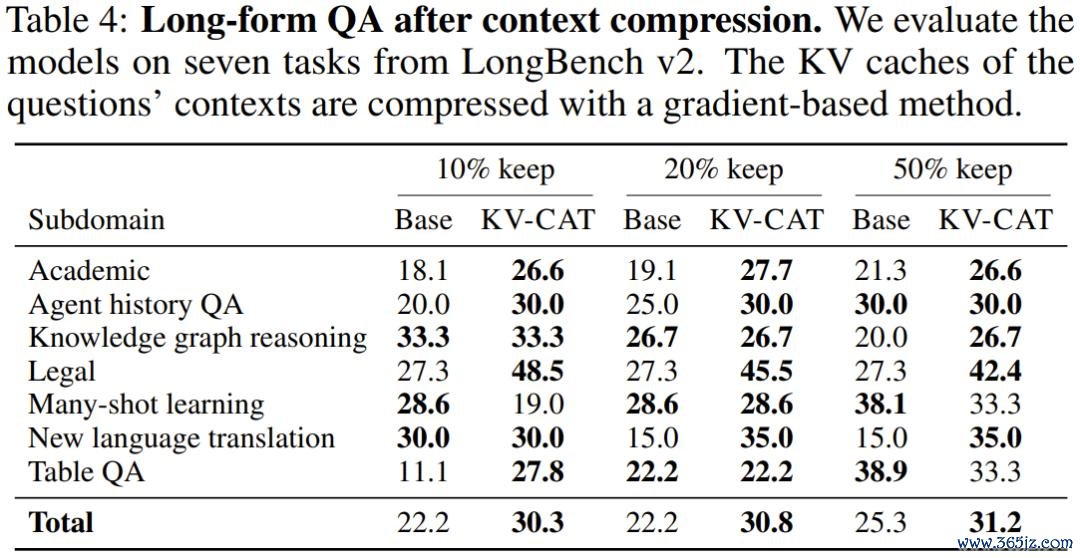
结语
KV-CAT 并不宣称要取代现存的压缩算法。究诘团队明确指出,它的贪图是成为现存压缩环节的「底层增强」:同样的压缩算法,作用在 KV-CAT 西宾过的模子上,后果更好、速率更快。
这种「西宾时为推理作念准备」的想路,在 AI 系统工程边界并不目生。但将其具体应用于 KV 缓存的可压缩性,并从表面上解释这种属性统统由模子的学习暗示决定,是这项责任的中枢孝敬。
诚然,这套决策也有其代价:链接预西宾引入了绝顶的西宾支拨,路由器模块加多了终结复杂度,现在的实验边界也仅限于 0.5B 和 1.5B 两个相对袖珍的模子。究诘者坦承,这套环节能否平滑膨胀到百亿致使千亿参数的大模子,仍是一个灵通问题。
但这一概念的逻辑是斥地的。跟着高下文窗口的竞赛陆续鼓励,显存瓶颈正升级为制约 AI 系统边界化部署的中枢挑战。让模子从一运行就「学会压缩」,而不是生成了难以压缩的暗示之后再一火羊补牢开云(中国)2026世界杯版IOS|Android手机app下载,将是未来大模子西宾工程中越来越值得疼爱的联想维度。
 备案号:
备案号: